

🎯 Réponse Rapide et Points Clés :
Claude Sonnet 4.5 est le dernier modèle d’IA d’Anthropic, lancé en septembre 2024. Présenté comme le meilleur modèle de codage au monde, il excelle dans la création d’agents complexes et peut travailler de manière autonome pendant 30 heures sur un projet, contre 7 heures pour sa version précédente.
Les points essentiels à retenir :
- Taux de réussite de 60% sur les benchmarks de codage (contre 42% pour Sonnet 4)
- Tarification accessible : 3$ par million de tokens d’entrée et 15$ en sortie
- Disponible sur AWS Bedrock, Google Cloud Vertex AI et l’API Anthropic
Le Nouveau Champion du Développement Logiciel
Anthropic frappe fort. Quatre mois seulement après Sonnet 4, la startup américaine fondée en 2021 par d’anciens chercheurs d’OpenAI dévoile Claude Sonnet 4.5. Et les chiffres parlent d’eux-mêmes.
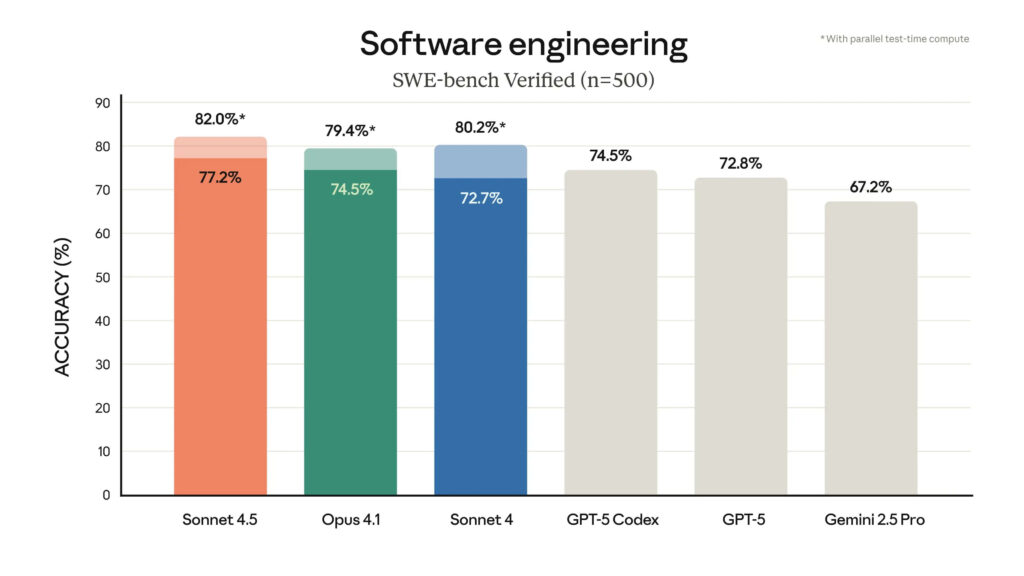
Le modèle atteint désormais 60% de réussite sur les tâches de programmation complexes. Un bond de 18 points par rapport à son prédécesseur. Plus impressionnant encore : Replit, plateforme de développement collaborative, rapporte un taux d’erreur passé de 9% à 0% sur son benchmark interne d’édition de code.
La différence ? Une compréhension contextuelle qui transforme radicalement la vitesse de développement. Du débogage à l’architecture système, Claude Sonnet 4.5 gère l’ensemble du cycle de développement avec une précision inédite.
Des Agents Autonomes Capables de Travailler 30 Heures Non-Stop
L’autonomie change la donne. Là où Sonnet 4 plafonnait à 7 heures de travail continu sur un projet, la version 4.5 tient 30 heures. Quatre fois plus longtemps.
Concrètement ? Le modèle peut développer une application complète sans intervention humaine. Il planifie, code, teste, corrige et itère. Seul.
Cette capacité repositionne Claude comme l’outil de référence pour construire des agents logiciels complexes. Des systèmes capables d’interagir avec des environnements techniques sophistiqués, de prendre des décisions et d’exécuter des tâches de bout en bout.

Computer Use : Quand l’IA Contrôle Votre Ordinateur
La fonctionnalité « Computer use » marque un tournant. Claude Sonnet 4.5 peut désormais manipuler directement votre interface : cliquer, taper, naviguer entre applications. Comme un utilisateur humain.
Les cas d’usage explosent :
- Automatisation de workflows complexes nécessitant plusieurs outils
- Tests d’applications en conditions réelles d’utilisation
- Déploiement et monitoring d’infrastructures cloud
Cette capacité séduit particulièrement deux secteurs : la cybersécurité et la finance. Dans le premier cas, le modèle détecte, analyse et corrige les vulnérabilités avec une rapidité redoutable. Dans le second, il traite des volumes massifs de données structurées et non structurées pour des analyses approfondies.
Une Bataille Frontale Contre GPT-5
Le timing n’est pas anodin. Anthropic lance Sonnet 4.5 en réponse directe à GPT-5 d’OpenAI. Et sur le terrain du codage, Claude prend l’avantage.
Les benchmarks indépendants confirment : Sonnet 4.5 surpasse GPT-5 sur les tâches de programmation, particulièrement pour le raisonnement sur données tabulaires et multimodales. Box AI, dans son évaluation entreprise, souligne cette « amélioration transformationnelle » dans la compréhension de données complexes.
La différence stratégique ? Anthropic mise tout sur la fiabilité et la précision. Là où OpenAI cherche la polyvalence maximale, Claude se spécialise. Et ça paie.

Intégrations et Disponibilité : L’Écosystème S’Élargit
Claude Sonnet 4.5 débarque partout. Amazon Bedrock l’intègre comme modèle phare pour les agents complexes. Databricks le propose via DBSQL pour appliquer l’IA à vos données gouvernées. GitHub Copilot le déploie dans VS Code et la CLI.
La stratégie d’Anthropic ? Multiplier les points d’accès. Le modèle reste disponible gratuitement sur claude.ai pour les utilisateurs standards. Les développeurs peuvent l’essayer via l’API avec un crédit initial. Les utilisateurs Pro (15€/mois) bénéficient de limites étendues.
Cette approche démocratise l’accès tout en monétisant les usages professionnels intensifs. Un équilibre rare dans l’industrie.
Sécurité et Alignement : Les Garde-Fous d’Anthropic
La puissance appelle la responsabilité. Anthropic l’a compris. Chaque version de Claude intègre des mécanismes d’alignement renforcés.
Le modèle refuse les requêtes dangereuses. Il explique ses limites. Il cite ses sources quand il le peut. Cette transparence rassure les entreprises qui déploient l’IA dans des contextes sensibles : droit, santé, recherche scientifique.
Mais la prudence reste de mise. Les performances impressionnent sur les benchmarks. La maturité en production réelle demande encore du temps et des validations terrain.
Performance Technique et Benchmarks Détaillés
Les chiffres techniques révèlent l’ampleur du progrès. Sur SWE-bench, référence pour évaluer les capacités de codage, Sonnet 4.5 grimpe à 60% de résolution. GPT-5 stagne à 52%.
Sur les tâches multimodales combinant texte, images et tableaux, l’écart se creuse encore. Box AI rapporte une amélioration de 40% dans le raisonnement sur données structurées complexes.
La latence diminue aussi. Les temps de réponse s’améliorent de 15% par rapport à Sonnet 4, malgré une complexité accrue du modèle. Une prouesse technique qui rend l’expérience utilisateur plus fluide.

Perspectives et Limites : Où Va Claude ?
L’accélération impressionne. Quatre mois entre deux versions majeures. Un rythme d’innovation jamais vu dans l’IA générative.
Mais des questions demeurent. La fiabilité sur des projets de plusieurs semaines reste à prouver. Les hallucinations, bien que réduites, persistent. Le coût énergétique de ces modèles géants pose des questions de durabilité.
Anthropic promet des mises à jour régulières. L’écosystème se structure. Les intégrations se multiplient. Claude devient une infrastructure sur laquelle d’autres construisent.
Le pari : faire de Sonnet 4.5 la référence pour les agents logiciels autonomes. Un marché qui explose. Une course que personne ne veut perdre.
Conclusion
Claude Sonnet 4.5 redéfinit les standards du codage assisté par IA. Avec 60% de réussite sur les benchmarks, 30 heures d’autonomie et une intégration massive dans les outils développeurs, Anthropic positionne son modèle comme l’infrastructure de référence pour les agents logiciels. Les performances dépassent GPT-5 sur le terrain du développement, tandis que la tarification reste accessible aux équipes de toutes tailles.
Prochaine étape : Testez Claude Sonnet 4.5 gratuitement sur claude.ai ou explorez l’API Anthropic pour intégrer ces capacités dans vos workflows de développement. L’ère des agents autonomes commence maintenant.